Deep Education
The advancements in the deep learning field are happening very quickly, newer and faster models are coming out everyday. Many companies are adopting every new technology that comes out but the adoption of those new technologies can be a bit slower in the educational system. The application and benefits of applying deep learning models and techniques are explored in this project. The significance of this project is in applying new models on domain specific data using a raw text corpus. At the end of the project I deduce that using RNN on word level prediction combined with beam search is a promising field. Document similarity using paragraph vectors are also tested and found to be the right model for many applications including course recommendation.
The main aim of this project is to produce models that can be used in a tool that will facilitate the process of course exploration by students. First two recurrent neural nets (RNN) are trained, one on the word level and the other on the character level prediction. The hyper-parameters are tweaked and fine-tuned to produce the best possible model without overfitting on the data. Test cases are defined and then applied on every model. The other part of the tool is a text similarity module. Word embeddings are used to find distances between documents, in our case, documents = courses. This aims to show that the difference in the materials of the courses will be visible in the distance between their word vectors.
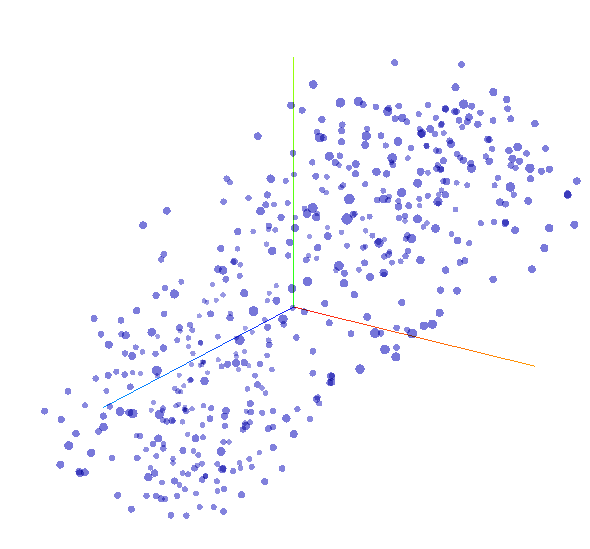
Our word embeddings
Data
The base dataset was the data obtained from the Software Development Management Specialization MOOC that the University of Alberta offers on Coursera. The transcripts of the video lectures were used. However, all the transcripts combined would only form 79 KB of text. Any RNN model used would overfit on this amount of data. So, a few books, reports, and Wikipedia articles were gathered from the web and used for training. One constrained was put in place was to only look for data in the software development field. Finding a field specific text corpus that suites the needs of this project wasn’t straight forward. Most of the documents found were in PDF format. When PDF is converted to text, many formattings are lost and cause problems for the models to process. Effort was done to make the data as clear as possible and the distracting symbols, such as dots in the table of contents, were cleaned.
Main parts
- Text Generation
- Character-level generation
- Word-level generation
- Document Similarity
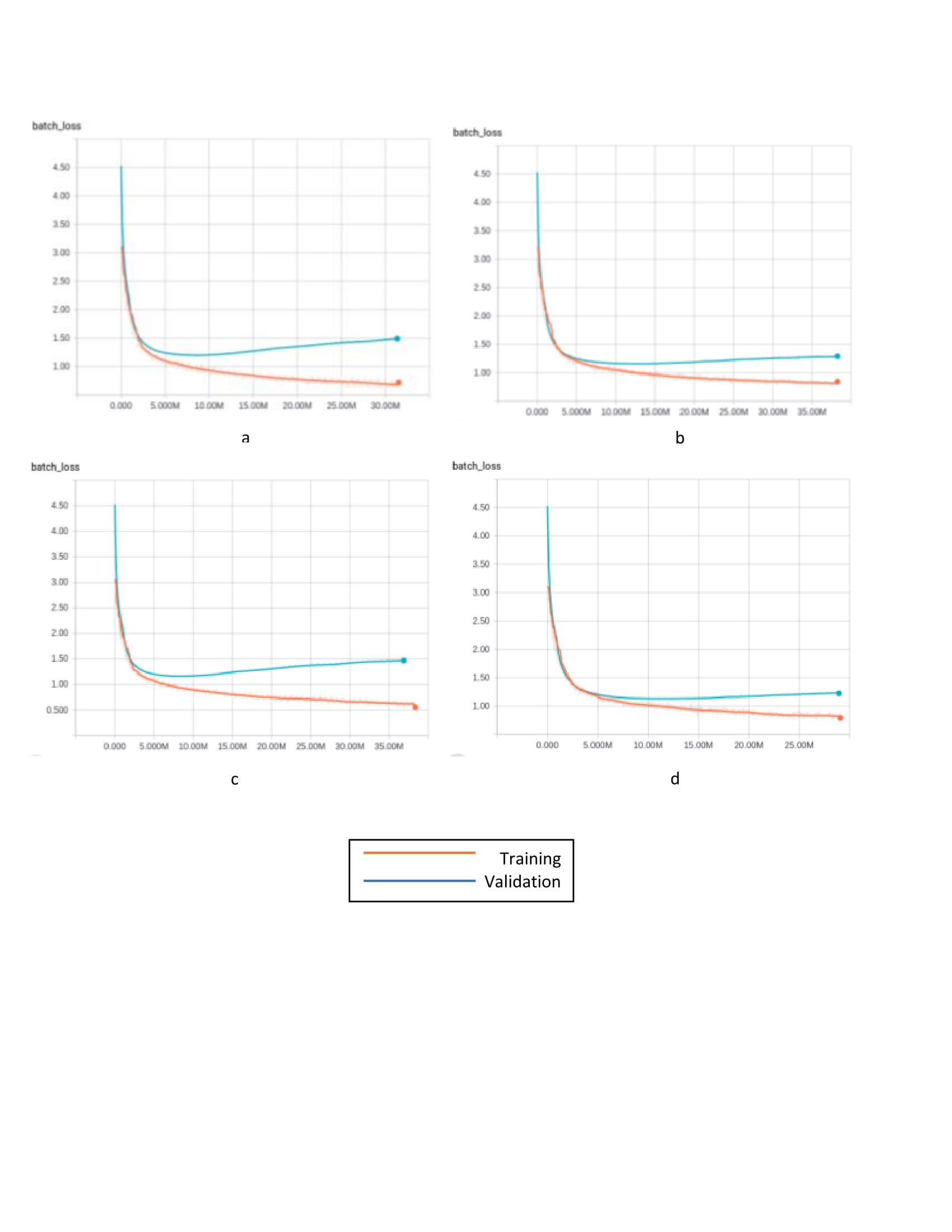
Losses